Wan2.2
综合介绍
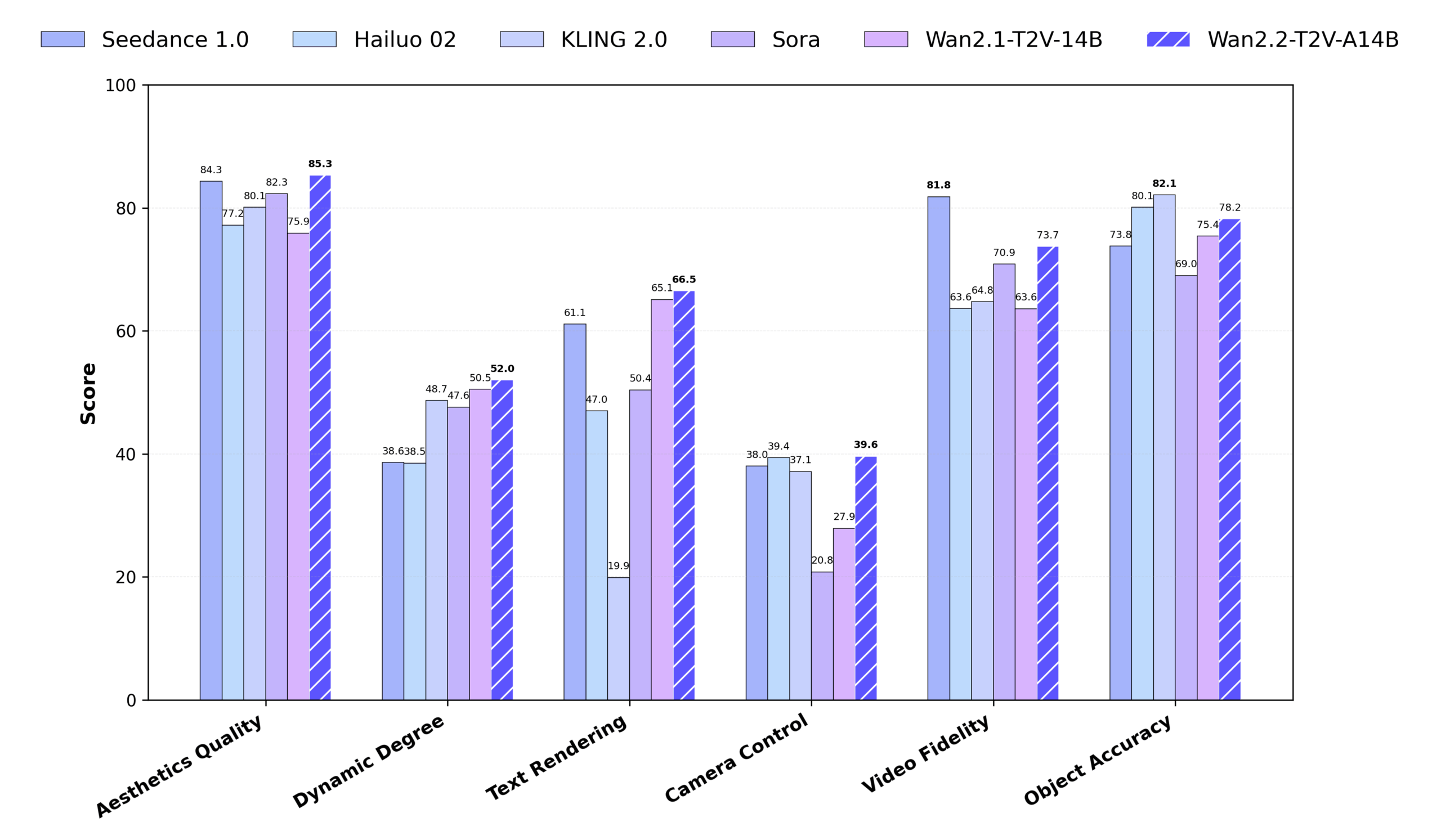
Wan2.2 是由阿里巴巴通义实验室研发的开源视频生成模型,在其先前版本的基础上进行了重大升级。该模型的核心创新在于首次将混合专家(MoE)架构引入视频扩散模型中,通过两个各约14B参数的专家模型(一个处理高噪声阶段的整体布局,一个处理低噪声阶段的视频细节)在不增加推理计算成本的前提下,有效提升了模型性能和视频生成质量。为了实现电影级的审美控制,Wan2.2在训练中使用了带有光照、构图、色调等精细化标签的美学数据,让用户能生成风格可控的视频。同时,模型训练数据量大幅增加(图像增加65.6%,视频增加83.2%),显著增强了对复杂动作和语义的理解能力。此外,项目还开源了一个高效的5B参数混合模型(TI2V-5B),该模型采用压缩比高达16×16×4的先进VAE(变分自编码器),支持在消费级显卡(如RTX 4090)上运行,能生成720P@24fps的视频,是目前速度最快的同规格开源模型之一。
功能列表
- 混合专家(MoE)架构:内置两个专家模型,分别处理视频去噪的早期和晚期阶段,在不增加推理成本的情况下,显著提升了视频的整体布局感和细节精致度。
- 文生视频(Text-to-Video):基于
T2V-A14B模型,输入文本描述,可直接生成480P或720P分辨率的视频。 - 图生视频(Image-to-Video):基于
I2V-A14B模型,输入一张图片作为参考,结合文本描述或让模型自动理解图片内容,生成动态视频。支持480P和720P分辨率。 - 高效图文生视频(TI2V):由一个5B参数的统一模型支持,结合了高压缩率的VAE技术,可以在消费级显卡上高效生成720P@24fps的视频,同时支持文生视频和图生视频两种模式。
- 电影级美学控制:通过在提示词中加入光照、构图、色调等描述,可以对生成视频的视觉风格进行更精确的控制。
- 提示词扩展:支持集成外部大语言模型(如阿里云的Dashscope API或本地Qwen模型)来优化和丰富输入的文本提示,从而生成细节更丰富的视频。
- 图生视频(无提示词):在图生视频模式下,可以不提供任何文本提示,模型将自动分析输入图片的内容,并生成相应的动态视频。
- 多GPU推理:支持使用PyTorch
FSDP和DeepSpeed Ulysses等技术进行多GPU加速,以处理更大规模的模型和更高分辨率的视频生成任务。 - 社区集成支持:已被集成到多个主流工作流工具中,包括
ComfyUI,Diffusers以及DiffSynth-Studio,方便不同习惯的用户使用。
使用帮助
Wan2.2是一个基于命令行的工具,用户需要在本地配置好Python环境后,通过在终端输入命令来使用。
1. 环境安装
首先,将项目代码克隆到本地:
git clone https://github.com/Wan-Video/Wan2.2.git
cd Wan2.2
然后,安装所有必需的依赖库。官方要求PyTorch版本不低于2.4.0。如果flash_attn安装失败,可以先安装其他库,最后再单独处理它。
pip install -r requirements.txt
2. 模型下载
Wan2.2提供了三种核心模型,您需要根据需求下载。
| 模型 | 下载渠道 | 描述 |
|---|---|---|
| T2V-A14B | 🤗 Huggingface 🤖 ModelScope | 文生视频MoE模型, 支持480P和720P |
| I2V-A14B | 🤗 Huggingface 🤖 ModelScope | 图生视频MoE模型, 支持480P和720P |
| TI2V-5B | 🤗 Huggingface 🤖 ModelScope | 高压缩VAE,图文生视频统一模型, 支持720P@24fps |
您可以使用huggingface-cli或modelscope-cli进行下载,以T2V模型为例:
# 使用 Hugging Face
huggingface-cli download Wan-AI/Wan2.2-T2V-A14B --local-dir ./Wan2.2-T2V-A14B
# 或者使用 ModelScope
modelscope download Wan-AI/Wan2.2-T2V-A14B --local_dir ./Wan2.2-T2V-A14B
3. 功能操作流程
以下是各项功能的具体操作命令。
文本生成视频 (Text-to-Video)
使用T2V-A14B模型。
- 单GPU推理 (至少80GB显存)
python generate.py --task t2v-A14B --size 1280*720 --ckpt_dir ./Wan2.2-T2V-A14B --prompt "两只拟人化的猫,穿着舒适的拳击装备和明亮的拳击手套,在聚光灯下的舞台上激烈地打斗。"💡 如果遇到显存不足(OOM)问题,可以添加
--offload_model True,--convert_model_dtype,--t5_cpu这三个参数来将部分计算卸载到CPU,以减少GPU显存占用。 - 多GPU推理
torchrun --nproc_per_node=8 generate.py --task t2v-A14B --size 1280*720 --ckpt_dir ./Wan2.2-T2V-A14B --dit_fsdp --t5_fsdp --ulysses_size 8 --prompt "一只猫在打拳击"
图像生成视频 (Image-to-Video)
使用I2V-A14B模型。
- 单GPU推理 (至少80GB显存)
python generate.py --task i2v-A14B --size 1280*720 --ckpt_dir ./Wan2.2-I2V-A14B --image examples/i2v_input.JPG --prompt "夏日沙滩度假风,一只戴着墨镜的白猫坐在冲浪板上。"💡 在图生视频任务中,
size参数代表生成视频的总像素面积,视频的宽高比将自动与输入的图片保持一致。 - 无提示词的图像生成视频模型可以仅根据输入的图像内容生成视频。此时,建议启用提示词扩展,让模型先从图像中生成描述。
DASH_API_KEY=your_key torchrun --nproc_per_node=8 generate.py --task i2v-A14B --size 1280*720 --ckpt_dir ./Wan2.2-I2V-A14B --prompt '' --image examples/i2v_input.JPG --dit_fsdp --t5_fsdp --ulysses_size 8 --use_prompt_extend --prompt_extend_method 'dashscope'
高效图文生成视频
使用TI2V-5B模型,该模型非常适合在消费级显卡上运行。
- 单GPU推理 (至少24GB显存,如RTX 4090)
# 文生视频 python generate.py --task ti2v-5B --size 1280*704 --ckpt_dir ./Wan2.2-TI2V-5B --offload_model True --convert_model_dtype --t5_cpu --prompt "两只拟人化的猫在打拳击" # 图生视频 python generate.py --task ti2v-5B --size 1280*704 --ckpt_dir ./Wan2.2-TI2V-5B --offload_model True --convert_model_dtype --t5_cpu --image examples/i2v_input.JPG --prompt "戴墨镜的白猫坐在冲浪板上"💡 注意:此模型的720P分辨率为
1280*704或704*1280。如果提供了--image参数,则执行图生视频任务;否则默认为文生视频任务。
4. 使用提示词扩展增强效果
为让视频细节更丰富,建议启用此功能。
- 使用Dashscope API:需要先申请
api_key。DASH_API_KEY=your_key torchrun --nproc_per_node=8 generate.py --task t2v-A14B --size 1280*720 --ckpt_dir ./Wan2.2-T2V-A14B --prompt "一只猫在打拳击" --use_prompt_extend --prompt_extend_method 'dashscope' --prompt_extend_target_lang 'zh' - 使用本地模型:默认使用HuggingFace上的Qwen模型。
torchrun --nproc_per_node=8 generate.py --task t2v-A14B --size 1280*720 --ckpt_dir ./Wan2.2-T2V-A14B --prompt "一只猫在打拳击" --use_prompt_extend --prompt_extend_method 'local_qwen' --prompt_extend_model Qwen/Qwen2.5-7B-Instruct
5. 不同GPU的计算效率
官方提供了在不同GPU配置下生成5秒视频的性能测试结果,格式为“总时间(秒) / 峰值GPU内存(GB)”。
- TI2V-5B (720P):
- 单张RTX 4090 (24GB):约 535.1秒 / 22.2GB
- 单张H100 (80GB):约 221.4秒 / 25.1GB
- 8卡 H100:约 36.4秒 / 24.8GB
- T2V-A14B (720P):
- 单张H100 (80GB):约 561.4秒 / 74.5GB
- 8卡 H100:约 76.5秒 / 73.1GB
这些数据表明,TI2V-5B模型在消费级显卡上实现了高效运行,而A14B模型则需要专业级硬件支持。
应用场景
- 短视频内容创作创作者可以利用Wan2.2将文字脚本或单张概念图快速转化为动态视频。例如,输入“一个男孩在森林里,阳光穿过树叶,形成光晕”,即可生成具有电影感的“森林男孩”场景,极大地降低了视频制作的门槛。
- 广告与营销内容制作企业可以为产品快速生成生动的广告视频。例如,输入一张产品图片,并描述“产品在霓虹灯下的城市雨夜中穿梭”,即可生成充满动感的广告片段,用于社交媒体推广或创意构思。
- 复杂动态场景模拟对于需要表现复杂或高难度动作的场景,如“一群舞者在街头表演嘻哈舞蹈”或“滑板运动员在城市障碍中穿梭”,Wan2.2能够生成流畅且动作连贯的视频,可用于体育分析、影视预览等。
- 艺术与实验性影像探索艺术家可以输入抽象的描述,如“水彩风格的墨水在纸上散开,形成一座小岛,一艘纸船漂向岛屿”,来创造具有独特美学风格的视觉艺术作品。
QA
- Wan2.2对电脑硬件有什么要求?
- TI2V-5B模型:推荐使用至少有24GB显存的独立显卡,如NVIDIA RTX 3090或RTX 4090。
- T2V/I2V-A14B模型:需要专业级硬件,推荐使用至少80GB显存的显卡,如NVIDIA A100或H100。普通家用电脑的集成显卡无法运行。
- 什么是混合专家(MoE)架构,它有什么作用?这是一种高效的模型设计。在Wan2.2中,它由两个功能不同的专家模型组成:一个“高噪声专家”,在生成视频的初始阶段负责构建整体结构和动态;另一个“低噪声专家”,在后期负责精炼画面的细节和质感。这种分工合作的方式,可以在不增加实际计算量的情况下,让模型的总参数量变得更大,从而提升最终视频的质量。
- 生成视频可以用于商业用途吗?可以。该项目采用Apache 2.0许可证,允许商业使用。官方声明对用户生成的内容不主张任何权利,但使用者必须对自己生成的内容负责,确保其符合法律法规,不能用于任何非法或有害的用途。
- 我输入的中文提示词效果不佳怎么办?强烈建议启用提示词扩展功能。通过在命令中加入
--use_prompt_extend和--prompt_extend_target_lang 'zh'参数,系统可以调用一个更强大的大语言模型(如Qwen)来将您的中文短句优化、翻译并扩展为模型更擅长理解的、细节丰富的英文长描述,从而显著提升生成视频的质量。